Introduction to Continuous Deployment
We rely increasingly more on web services in our lives. We cannot think of our world without the web services of Google, Facebook, Twitter and many others. But as we rely more and more on these services, we are less accepting when such a service is temporarily offline - regardless of whether this was due to a failure or maintenance. This puts additional strain on teams which are responsible for improving and operating these services. Especially when a web service has to be updated to a newer version while still remaining online and available to its users. In this text we’ll explore some of the ways to achieve Continuous Deployment and the challenges that come with it.
What is Continuous Deployment?
In recent years development teams have been transitioning to alternative methods of development. Moving towards more Agile methodologies and concepts they are now able to produce production-ready deliverables on a continuous basis. These deliverables are automatically - and continuously - tested using an automated unit- and integration test suite. By being able to produce these production-ready deliverables in quick succession, these development teams are able to quickly adapt to customer requirements and are quick to deal with bugs. But being able to produce these deliverables in a continuous pace is not enough to fulfill customer requirements. These deliverables must also be deployed into production for customers to benefit from these improvements. This is where Continuous Deployment comes into view.
The goal of Continuous Deployment is to ensure that (almost) every production-ready deliverable is automatically deployed to all production servers, thereby replacing the older version. There are various tools, techniques and strategies to achieve this, each with their own advantages and disadvantages. In this post I will focus only on this upgrade process.
The Art of Load balancing
Deploying a new version of a web service without causing downtime is typically done using some form of load balancing. A load balancer is a piece of software which sits between the various servers running the web service - called a server pool - and the connection to the internet. A load balancer is able to redirect incoming user requests to one particular server in the server pool based on a set of rules. By changing these rules, one is able to remove a server from the server pool - effectively not letting that server process anymore user requests, or adding a server to the server pool - which will cause some of the traffic to be redirected to that server. There are two strategies available using a load balancer which can help teams deploy new versions of their web service without the need to go offline. These are known as “rolling upgrades” and “big-flips” (also known as atomic switches).
Rolling upgrades
The typical setup for rolling upgrades is one (or more) load balancers redirecting incoming user traffic to a set of servers. This group of servers is called a server pool. When you wish to upgrade a server, you instruct the loadbalancer to remove that server from the server pool. In essence this means that the server will no longer receive any traffic coming through the load balancer from users. You can then gracefully terminate, upgrade, and restart the service(s) installed on the server safely. When these steps have been completed, the server can be re-added to the server pool. As a result the server will then start receiving traffic again through the load balancer. This procedure completes when every server has been taken from the server pool, is upgraded, and then re-added to the server pool.
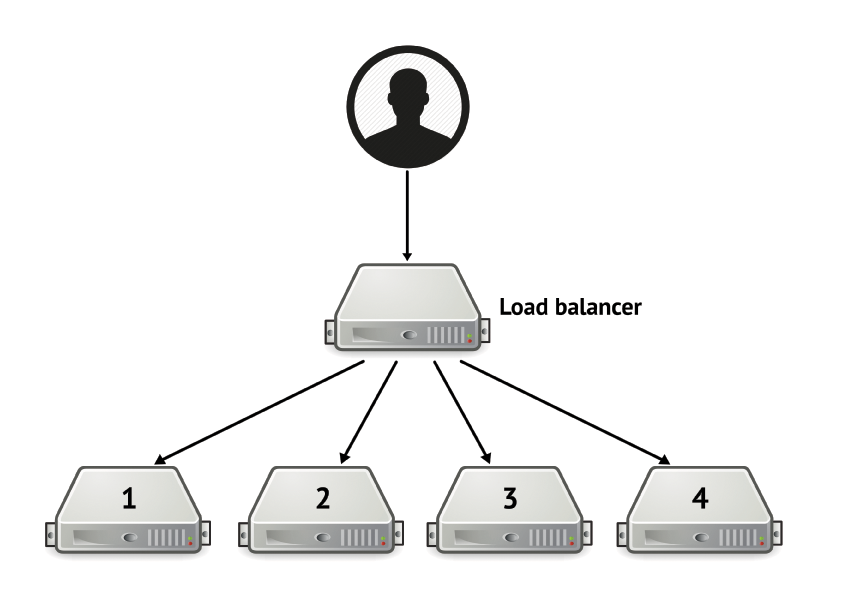
To avoid a significant loss of capacity or performance you can choose to upgrade one server at a time. This is usefull for small environments with few servers where there is little over-provisioning of computing resources. Alternatively you can also choose to upgrade several servers concurrently, which will take less time to complete the entire upgrade, but will adversely affect your capacity and maybe even performance of your web service.
Big-flips
Another option is the use of big-flips (also known as atomic switches). With big-flips you need a different setup of your servers. You will typically have a load balancer which redirects incoming user traffic to a server pool much like with rolling upgrades, but when you wish to perform an upgrade to your service you will need a duplicate server pool with equivalent resources to take over the workload from the initial server pool. So in order to perform the actual upgrade you must first install the upgraded version of the service on the alternate server pool. When that has been done, you will need to instruct the load balancer to stop redirecting traffic to the initial server pool, and instead redirect it to the alternate server pool. You can then safely terminate the services running on the initial server pool and release the computational resources used in this server pool.
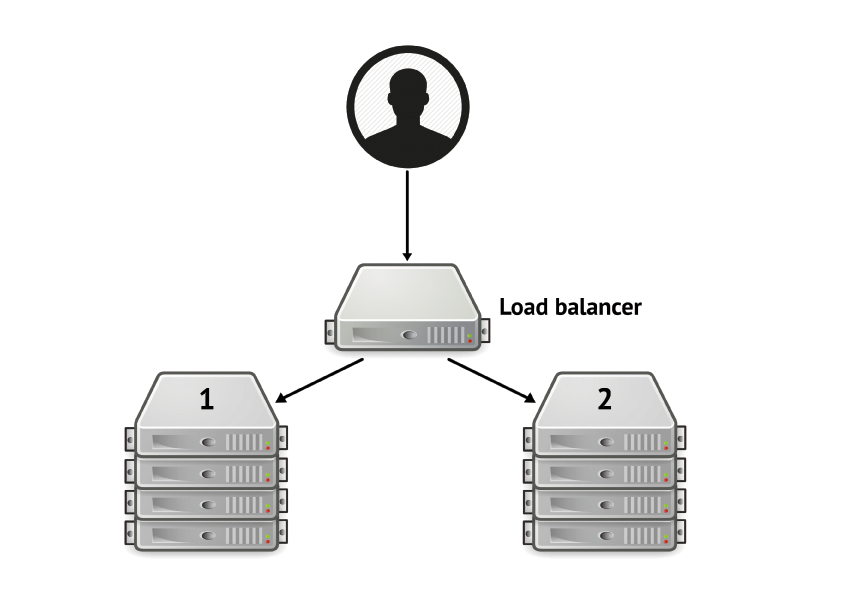
Big-flips are very costly in terms of computational resources. For every upgrade you require a duplicate of your production environment, and only for a very short period of time when you are performing the upgrade. This can partially be offset by using cloud providers which will rent you these computational resources per minute or hour and allow you to dispose of the initial server pool once the upgrade has succesfully completed.
Trade offs
I’ve briefly introduced you to two different strategies you can use to deploy a new version of a web service. You might have noticed that these two have two very different types of “cost” and “advantage”. While rolling upgrades are slow when doing an entire upgrade sequentially for every server, they are very effecient in terms of computational resources - they require very little over-provisioning of resources, whereas big flips are quicker to perform the upgrade they require double the computational resources, which can be (too) costly.
So in a sense these two strategies sit at opposite ends of the same trade off: Effecient use of computational resources or a faster upgrade process.
The challenge of mixed-state
An often ignored part of achieving Continuous Deployment is the term “Mixed-state”. No upgrade or deployment is immune to it, and has to come up with some way of dealing with it. When you envision the entire web service - running on multiple servers - as a distributed software system, you need to ensure that every separate part can interface correctly with its dependencies. Mixed-state refers to the situation where mid-upgrade or mid-deployment you have two versions of the same software running concurrently, using the same dependencies. In a sense, the distributed software system is in two states now. This means that any dependency on which both versions operate, must be compatible with both versions. This is typically solved using versioned and static APIs which allow dependencies to communicate amongst each other without problems. There is however one notable exception: databases.
Imagine running two versions of the same web service on the same database, which has stored all its persistent data in some structure or schema. If the never version requires a slightly different schema, the older version might cease to function which could result in breaking the web service, until the upgrade of the system has completed and moved from a mixed-state to a single state again. This is aggrevated when the upgrade process takes a long time to complete.
This is an ongoing challenge, there is no off the shelf solution, and in this upcoming blog series I will cover it more in-depth. I will be showing you some of my research and results in this area. Stay tuned for more…