Dealing With Mixed-state in SQL Databases
In the previous blog post I gave a very brief introduction to the concept of Continuous Deployment and how you can achieve it by using a load balancer. In this post I’ll be digging deeper into Continuous Deployment but mainly focussing on one of the biggest problems implementors of Continuous Deployment face: storing and retrieving data stored in databases. In particular SQL databases.
It’s a given that software evolves over time for various reasons: bug fixes, changing requirements, reducing technical debt, or various other reasons. As a consequence, that means that the way software stores and retrieves persistent data, also changes over time. Many (web)-applications use relational databases to store persistent data. In particular SQL databases like MySQL, PostgreSQL, MSSQL or Oracle are used often. The SQL language and concepts themselves were introduced in the 1980s, and have remained largely unchanged. Despite the growing popularity of NoSQL alternatives, they still remain to be extensively used in most web applications in some capacity.
A more accurate problem description
Today’s relational SQL databases actually have two problems when used in a Continuous Deployment setting. The first and most obvious problem is dealing with the blocking nature of some operations in SQL databases, making schema evolution in SQL databases prohibitive in live production environments. The second and less obvious problem is dealing with mixed-state. This is a problem NoSQL databases also face, but is largely ignored in both areas.
Dealing with the blocking nature of DDL statements
DDL statements are statements which describe an action on the schema of a database. Examples would be creating a table, or dropping a column, or adding a foreign key. In SQL databases these operations are often regarded as statements used during maintenance, and often assume that the database is not in active use while they are performed. As a result, database developers have implemented them in such a way that they often require a write lock on the entire table and thus don’t play very well with other DML queries. In addition they are typically slow and disruptive under stressed circumstances. If you want your software to be continuously deployable, you will need to find a way around these blocking operations. This greatly depends on the SQL database you are using and your use case (nature of your application, method of application deployment, etc).
Dealing with mixed-state
As explained in the previous blog post, when you are in the process of evolving a schema from one version to the next there is a period of time where both versions of the schema are active. This period is more commonly referred to as the mixed-state. This mixed-state is due to the fact that even though the switchover from the old to the new version of the web application might be atomical, there is a period where both versions of the web application are active at the same time, although one is not yet handling incoming user requests. Both require a different schema to operate on, and can/should not operate on each other’s schema.
Current state of schema evolution in practice
If you wish to use relational databases in a production environment with Continuous Deployment there are currently two practical ways of doing this. The first is maintain everything manually, letting your application deal with the mixed-state and use a technique called expand-contract to evolve the database schema. The alternative is using a tool like the Percona toolkit, which will perform this expand-contract technique in an automated fashion, and performs an atomic table rename to switch from one schema to the other. Let’s examine why neither option is favorable.
Manual evolution
The first option is to handle the evolution and migration manually. Let’s imagine we have a web application running in production on a certain database schema and our application is deployed using rolling upgrades. The SQL database currently contains a users table which holds information on every user that has ever registered with the web application. To be able to suspend the accounts of their users in some cases, the software engineers have decided that they want to add a new column called suspended to the users table, signifying if an account has been suspended or is still active. However simply executing a query which adds this column to the existing users table would require a write lock on the entire table, and block other queries from retrieving data or updating data in this table. Since this web application hosts many millions of users, and the users table itself if constantly used, this is deemed too costly since it would require some downtime.
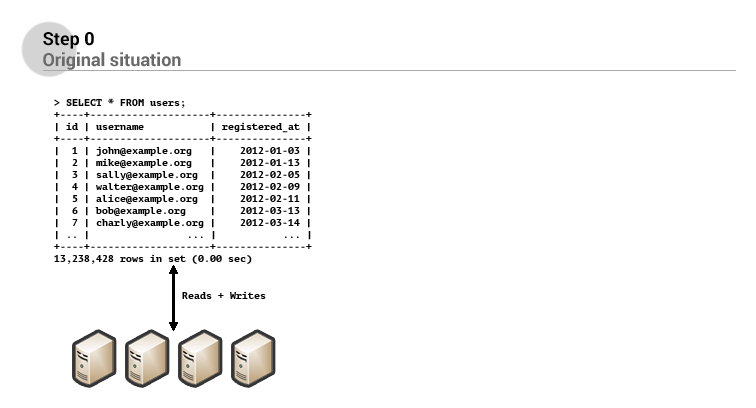
Instead the software engineers create a new table called users_v2 with the same columns that the original users table contains plus the new suspended column. Next they deploy a new version of the application which will read and write user information from and to the users table, but also write these records to the new users_v2 table whenever a change is made to one of the rows in the users table. In addition to this, they start a background task which copies over all entries in the users table to the new users_v2 table, to ensure that all users are copied within a finite amount of time.
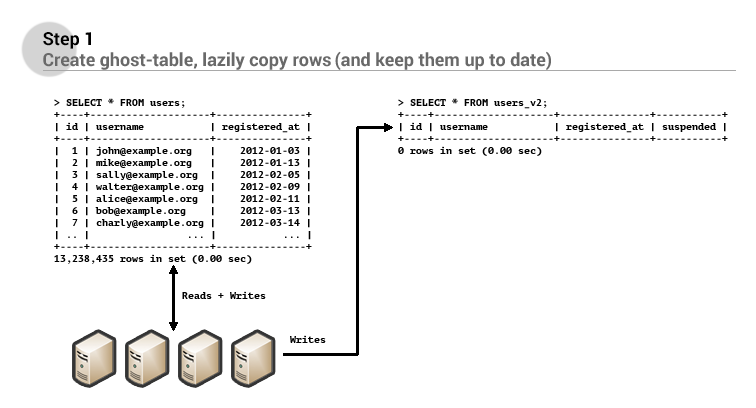
Finally when the two tables contain an equal amount of records, the migration has achieved the mixed-state successfully, and a new version of the application can be deployed which will read and write from the new users_v2 table, but also update the records in the users table if a records is changed in the users_v2 table. This has to be done since we’re using the rolling upgrades method to deploy our application. During the deployment of the new application two different versions are active and might write modifications to both the old and the new users table.
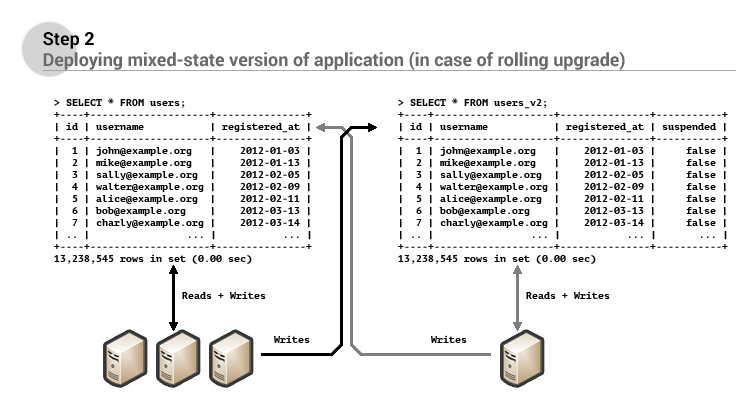
Once this deployment has completed another version of the application can be deployed which will only read and write from the new users_v2 table. Once this deployment has succesfully completed, the original users table may be deleted.

Please note that it is also possible to use triggers in many SQL databases to keep these two tables synchronized. Whenever a record is changed in a table that has a trigger added to it, it may run additional queries or snippets of code. If you add a trigger which upon changes in data in the users table, writes these changes to the users_v2, it is possible to keep these these two tables synchronized.
Evaluation
This might seem like a logical way to evolve the schema of the database under these strict conditions, but there are several issues with this method:
- Deploying a change to the schema of the database requires several (re)deployments of your web application, tightly tying schema changes to your application development. These in-between versions of the application are specifically aimed at dealing with mixed-state, and need to synchronize data between two tables. It would be a lot easier if you (as a developer) would not have to deal with this state.
- This method makes the application responsible for dealing with mixed-state situations. This means that the database layer in your application has to deal with this added complexity. Although not impossible it increases the complexity of the database layer.
- Probably the most useful feature in relational databases is the foreign key constraint. How do you deal with foreign key constraints in this method? A table like the
userstable is often referred to by other tables in web applications, so duplicating and replacing this table using this method while maintaining referential integrety through foreign key constraints is quite a challenge if not impossible. - How do you roll back your changes to the application and the schema of the database in case of problems? Perhaps it is no longer possible to deploy older versions of your application.
So there are quite some issues to think about before employing this method for evolving the schema of your database. Luckily there are some automated variations of this approach.
Automated evolution
So manually performing evolution of schema evolution is quite complex, and has a number of caveats. In this section I’ll cover some of the tools that automate the same process and which address some of these issues.
OpenArk Kit & Percona Toolkit
The first two tools are the OpenArk Kit and the Percona Toolkit. These toolkits consists of several utility command-line tools which handle everyday maintenance tasks for MySQL databases. Amongst these tools, there are two tools called “oak-online-alter-table” (OpenArk Kit) and “pt-online-schema-change” (Percona Toolkit), which aim to make ALTER TABLE operations on tables in MySQL databases non-blocking. They both do this by creating ghost-tables (also known as mirror-tables or shadow-tables), which is more or less the same process as we’ve seen in the Manual evolution section.
These tools create an empty ghost-table with the new structure based on the original table. They then install triggers on the original table which ensures that whenever a row is changed in the original table, that is reflected in the ghost-table. A background task then fills the ghost-table up with data originating from the original table. Once this process has completed, the names of the original and the ghost-table are swapped in an atomic table rename operation (either manually or automated), and the trigger is removed. This effectively completes the evolution.
If you study the documentation of these tools you’ll find that they do not support foreign keys very well. For instance OpenArk Kit, does not work when the table that is being modified has foreign keys defined on it. Percona handles things slightly better, but is also not sufficient. For instance the Percona documentation states the following about foreign keys:
Foreign keys complicate the tool’s operation and introduce additional risk. The technique of atomically renaming the original and new tables does not work when foreign keys refer to the table.
In order to deal with this situation, it offers the following options:
- rebuild_constraints, which basically means that the foreign keys are dropped and re-recreated (a process which itself can take very long and as you’ll see in the next blog post is also blocking).
- drop_swap, this method first disables foreign key checks for the entire database. This means that referential integrity is no longer enforced, and will allow the database to become inconsistent/invalid. Then the original table is dropped (a process which cannot be rolled back), and then the new table is renamed to the original table’s name effectively taking its place. At this point the foreign keys check can be re-enabled.
- none, which does the same as drop_swap but does not rename the new table to the original table’s name.
Facebook’s Online Schema Change
Facebook being Facebook, has created its own solution to this problem. Online Schema Change (OSC) is a tool for MySQL databases which does things slightly different. OSC creates an exact copy of the original table (both structure and data). In the mean time OSC captures all changes that happen to rows stored in the original table using triggers. These triggers store the modifications in a deltas table. Once the copy has been created OSC applies the operation on the ghost-table that was originally intented to be execute on the original table (for example adding a column). Since these operations often block this step may take a while. Once this operation has completed, OSC then starts replaying all the changes that happened to the original table from the deltas table onto the modified ghost-table. The final step is the “cut-over” step which atomically swaps the table names for both the original table and the ghost-table, when the deltas table has (almost) been exhausted.
However, as it turns out, OSC also does not support foreign keys. One of the limitations of OSC (see link above) is that there should no foreign keys present on the table to migrate.
Table Migrator
Table Migrator is another attempt at solving this problem for MySQL databases. Like the previous approaches it creates a ghost-table and applies the changes to this table that should originally be applied to the original table. However it does not copy data over using triggers, but a background process which copies batches of rows from the original table to the ghost table. To do this correctly, it requires a column called updated_at (if the row is mutable) or created_at (if the row is immutable), which stores a timestamp when the row was modified or created. By comparing the timestamps of the original table and the ghost-table it can determine which records are outdated in the ghost table and must be updated using data from the original table. It does this in multiple passes over all records in the original table, until only a small number of rows is still outdated. At this point it acquires a write lock on the table (blocking other queries from using that table), copies over the last remaining outdated rows, and swaps the table names for both tables before releasing the write lock again.
This approach does not use triggers like the other solutions use, but also does not support foreign keys. In addition it seems to require some additional instructions when rows can be deleted from the original table during migration in order to stay consistent. Interestingly enough this tool does attempt to integrate with ActiveRecord, which perhaps allows for some better version management of database schema changes. The other tools covered so far are command-line tools, which have no support for versioning database schemas.
SoundCloud’s Large Hadron Migrator
The last solution I’ll cover in this blog post is SoundCloud’s Large Hadron Migrator (LHM). LHM is also aimed at evolving schema of MySQL databases. LHM creates a journal table which will record modifications to the original table (using triggers) much like OSC created and populated the deltas table. In addition LHM creates the ghost-table like all the other solutions have done, and applies its structural changes to this table instead of the original table. LHM will then proceed to copy data from the original table to the new ghost-table (up to data that was present at the start of the migration). Once this process has completed the table names are atomically switched, and the journal entries are replayed.
It’s worth noting that similar to previously covered solutions, LHM also does not support foreign keys.
Conclusion
- I’ve shown how manual schema evolution is no easy feat and introduced substantial complexity to the development of the web application.
- Foreign keys are pretty much not supported, significantly reducing the value of these tools and approaches.
- Versioning the evolution of the schema is difficult, and typically an afterthought.
- Evolution of schema is limited because only small steps can be undertaken. This hinders bigger refactorings of code when they require significant changes in the existing database schema.
- The tools covered in this blog post offer no solution for the mixed-state problem. They only aim at solving the problem of blocking DDL statements in SQL databases.
Next up
In the next blog post I’ll be covering some of my result of profiling DDL statements in both MySQL and PostgreSQL. Do these operations really show blocking behaviour? How so? How long? And how could this help me with evolving database schemas without causing downtime for its users.