Automated Web Application Testing for Humans
Web applications have become a very popular breed of software. The fact that the software needed to use a web application is already installed on every internet-capable computer adds to its appeal. For a software developer there are many different architectures and even more frameworks to choose from to build web applications with. But one important part of software development - testing - can be very hard in web applications.
There are a few tools out there to help you with testing web applications. The most popular one seems to be Selenium. Selenium offers you two options for creating automated tests for web applications: Selenium IDE, and Selenium WebDriver. Selenium IDE is a simple plugin for FireFox which enables you to record interactions with a browser and replay those interactions. It’s most suitable for testers without a programming background. Selenium WebDriver on the other hand allows testers with a programming background (or developers) to write their own automated tests, which can be run from JUnit tests. But while using these tools myself I found myself easily annoyed at how fragile these tests actually are. In order to understand why this is so you have to understand how Selenium works.
When you use Selenium IDE to record a session of interactions with your browser it’s actually looking at what events you are triggering on which elements in the Document Object Model (DOM). Most of these elements can be identified with a name, id or class attribute. Take for example the login screen of Google’s Gmail service. The username and password field are aptly named “Email” and “Passwd” in the DOM using the id attribute. So when we make a recording using Selenium IDE, it will know that I’m typing in those two fields, and store the interaction together with that id attribute.
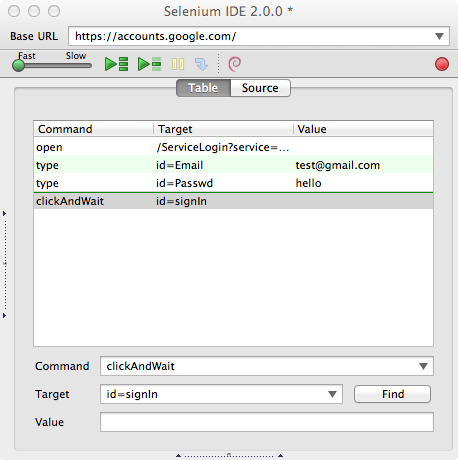
Although this is a fairly cheap way to construct a test, there are several problems with this approach:
- Tests are not necessarily repeatable: Web application frameworks like ExtJS and Google Web Toolkit produce different unique
idattribute values on every page serve. This means we need an alternative way of selecting the correct element in the DOM. There are several options like CSS and XPath selectors but these can get fairly complicated very quickly, which in turn negatively affects readability. - Tests are easily broken: When a developer or designer changes the structure of the DOM, there is a chance that certain CSS and XPath selectors will no longer work. Even worse, in case the name of the
idattribute is changed the test will definitely fail and it will have to be fixed. - Repairing tests means re-recording the interaction between user and browser: The cost of recording is relatively small, but if tests break regularly this can become prohibitively expensive. Imaging that most of your tests are done somewhere in a secured area of your web application. In order to get there, the browser first has to login into the web application. If this login page is modified, all of these tests will have to be either re-recorded or fixed manually.
- Test setup and tear down is expensive: In case you want to test a feature in your web application you are first required to log in, navigate to the appropriate page, perform the actual test, and log out. Such a test case can take considerable time to record, while the only important section is the actual test.
There is an obvious advantage in having an automated test suite which tests your web application from a user’s perspective, but these issues are making automated tests unwieldy and costly. The most sensible conclusion is that the approach of working on a DOM level is simply too low-level for creating and maintaining an extensive automated test suite. But now let’s approach this from a tester’s point of view. Most of the testers I know are very capable at writing test cases for manual regression testing. These test cases are well documented and manually executed before pushing software out to customers. These regression test documents usually have the following structure:
Preconditions: Your browser is displaying the login screen.
Procedure
- Enter “admin” in the “Username” field.
- Enter “test” in the “Password” field.
- Click on the “Login” button.
Postcondition: You are now logged in, and your browser should be displaying the user’s dashboard.
These regression test documents have a clear structure and are easy to read and maintain for testers. The reason that this works for human testers is that they can reason about what’s displayed in the browser. They know that the “Username” field is the field that has the text “Username” displayed right next to it. They know that the “Login” button is the element that’s clickable and contains the text “Login”. They know what the user’s dashboard looks like. My ideal test automation tool for web applications would be a tool which is capable of interpreting test documents like to one above, and execute them fully automatic.
If you iterate through all the issues I named earlier, you’ll notice that such a tool could easily address the first three issues in the list. Since test documents don’t specifically name attributes of elements in the DOM, it doesn’t really matter what the id attribute of any element says. Modifications to the DOM on a structural level don’t affect the interpretation of the presented web page to the same degree. And finally because this type of ‘recording’ is much more resilient to changes in the DOM, it should require only a minimal amount of test case maintenance, whilst the test cases themselves remain human-readable.
I’m very interested to see if it would be possible to create such a tool and to see if it indeed holds so much value for testers as I believe that it does…